I have always been curious about movie recommendation systems. Most recommendation systems involve using user data in collaborative filtering or content-based filtering systems. The idea behind the collaborative filtering system is that users who have similar preferences (who like the same movies) can give good recommendations to each other. The content-based system involves assigning some types of characteristics to each movie and recommend you new movies with similar characteristics as what you have liked in the past. A lot of people are probably familiar with using these systems in some popular platforms like Netflix or Amazon.
What I will talk about in this post is not one of these types of systems. It will not involve any user data. The recommendation systems that I just talked about are useful. They give you a list (or many lists) of movies you might like. But often when I want to find a movie to watch, I usually start by asking myself, “What am I in a mood for right now?” So I wanted to do a simple project that uses data on movie characteristics (assigned by tags), and let users answer a bunch of questions to get a movie recommendation at the end. Kind of like a game of twenty questions.
In this post, I will briefly go through building the model from data in Python (2.7). The web application itself was built using Django and is hosted on Heroku.
The Movie Data
To build this, we need data. Specifically, we need movies and tags associated with the movies. For this project, the data is from GroupLens Research. The MovieLens Tag Genome Dataset (released in 2014) contains about 1000 tags applied to about 10,000 movies. This is a good set to start the project off. We could update the project to include recent movies and a larger dataset in the future.
Import Pandas and Numpy.
import pandas as pd
import numpy as np
First, we read the tag-ID table. This table gives a tag name and its popularity. The tag popularity tells you how many times this tag is used.
#reading the tag-ID data
tags = pd.read_table(r'tags.dat',header=None,names=['tagID','tagName','tagPopularity'],encoding='utf-8');
Look at the most used tags.
>>> tags.sort_values(by=['tagPopularity'],ascending=False).head()
| tagID | tagName | tagPopularity | |
|---|---|---|---|
| 886 | 886 | sci-fi | 802 |
| 229 | 229 | comedy | 796 |
| 18 | 18 | action | 758 |
| 994 | 994 | surreal | 733 |
| 1049 | 1049 | twist ending | 728 |
#get rid of some unwanted tags
tags = tags.drop([467,762,464,805,786,98,535,96,970,993,445,463,971,468,451,720,444,553,338,269,
999,717,894,1072,1091,364,1071])
After dropping some unwanted tags (duplicates or tags containing spoilers), we do a count.
>>> tags.count()
tagID 1101
tagName 1101
tagPopularity 1101
dtype: int64
Now, read the movie ID table.
#read movie ID data
movies = pd.read_table(r'movies.dat',header=None,encoding='utf-8')
movies.rename(columns={0:'movieID',1:'movieName',2:'moviePopularity'},inplace=True);
Check out the table sorted by movie popularity.
>>> movies.sort_values(['moviePopularity'],ascending=False).head()
| movieID | movieName | moviePopularity | |
|---|---|---|---|
| 280 | 296 | Pulp Fiction (1994) | 70567 |
| 338 | 356 | Forrest Gump (1994) | 69786 |
| 558 | 593 | Silence of the Lambs, The (1991) | 66777 |
| 302 | 318 | Shawshank Redemption, The (1994) | 64442 |
| 455 | 480 | Jurassic Park (1993) | 63344 |
Next, read the tag relevance table. This table gives tag IDs that are assigned to each movie and their relevance score (between 0 and 1). The relevance score tells us how popular the tag is for the movie. If many people tagged the movie with this tag, the relevance score will be close to 1.
#read tag relevance data
tag_relevance = pd.read_table(r'tag_relevance.dat',header=None,encoding='utf-8');
tag_relevance.rename(columns={0:'movieID',1:'tagID',2:'tagScore'},inplace=True);
>>> tag_relevance.head()
| movieID | tagID | tagScore | |
|---|---|---|---|
| 0 | 1 | 0 | 0.032 |
| 1 | 1 | 1 | 0.035 |
| 2 | 1 | 2 | 0.070 |
| 3 | 1 | 3 | 0.114 |
| 4 | 1 | 4 | 0.105 |
Decision Tree
The way this application works is that we start with the full set of movies, and we eliminates subsets of movies with each input from a user. A user answering ‘yes’ to a tag will lead to a subset of movies with that tag. Answering ‘no’ will lead to a subset of movies without that tag. We keep asking questions until we eliminate all but one movie. This process can be described in a structure called a (binary) decision tree.
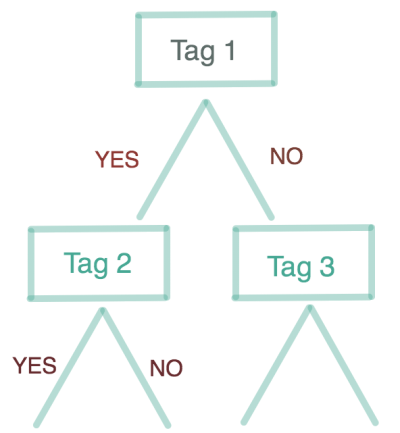
Each question about a tag represents a ‘node’ in the decision tree. Nodes at the bottom of the tree where there is only one movie in each node are called ‘leaf nodes’.
To build a decision tree, we need to decide which tag to use at each node. The main idea behind choosing a tag to use at each node is that the tag chosen should be good at separating the movies into two subsets. If a tag only applies to few movies in that subset, then it will not be very good at separating them.
We will be using Scikit-Learn library DecisionTreeClassifier to fit a tree to our data.
We need to first transform our data into a form that can be fed into DecisionTreeClassifier. What we would like is a table with movie ID in rows and tag ID in columns. Each row will represent a single movie with columns having values of 1 (if the tag in that column applies to the movie) and 0 (if it doesn’t apply). What we are doing is classifying which movies a set of tags corresponds to. Therefore, we are doing a multiclass classification where the number of classes is the total number of movies.
Let’s transform the data.
#function to prepare each movie data for concatnation
def prep_frame(frame, mid):
frame = frame.transpose()
frame.columns = frame.iloc[1]
frame.drop(frame.index[[0,1]], inplace=True)
frame.rename(index={'tagScore':mid}, inplace=True)
return frame
m = movies.index.size
n = tags.index.size
frame = tag_relevance[tag_relevance.movieID == movies.movieID.iloc[0]]
X = prep_frame(frame, movies.movieID.iloc[0])
#concat movie data one at a time
for i in range(1, m):
#get the movie ID
mid = movies.movieID.iloc[i]
#select all rows with the movie ID from tag_relevance table
frame = tag_relevance[tag_relevance.movieID == mid]
frame = prep_frame(frame, mid)
#concat dataframes
X = pd.concat([X, frame])
The data is ready. We can now build a decision tree.
from sklearn.tree import DecisionTreeClassifier
#fitting the Tree !!!
depth = 30
clf = tree.DecisionTreeClassifier(criterion='entropy', max_depth=depth)
clf = clf.fit(X, X.index)
We have the tree in clf.tree_ ! Let’s take a look at this tree. Visualizing the whole tree would be too much, so here’s an example of a part of a smaller tree.
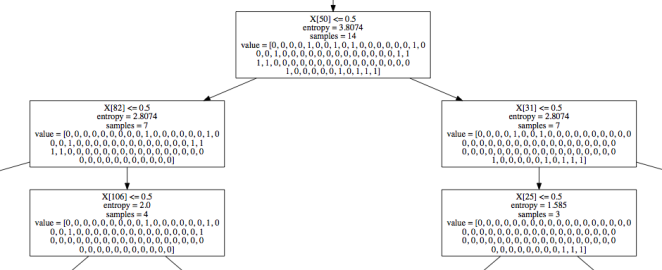
Each box represents a single node. The samples number shows the number of movies left in that node.
We can save this tree structure to be used in the web app. So let’s save the tree in a form that we can use. We need to know the left and right children of each node, the tag name of each node, and the movie names corresponding to each leaf node.
#building the Questions input
n_nodes = clf.tree_.node_count
children_left = clf.tree_.children_left
children_right = clf.tree_.children_right
feature = clf.tree_.feature
#create a feature name list
tagName = [tags_test.tagName.iloc[x] for x in feature]
for i in range(n_nodes):
if feature[i] == -2:
tagName[i] = u'None'
#and the movie name
movieName = [movies_test.movieName[movies_test.movieID == x].values[0] for x in X.index]
#write the movie prediction array to a file
np.save(r'prediction.npy',clf.tree_.value)
Save these lists into files to be used in the web app and we are done! The web app will start at the root node, ask if a user wants that tag, and traverse the tree until it reaches a leaf node. It will then respond with a recommended movie.
A next step in expanding this project would be to work with a larger set of data, update the data and the tree with new movies, and introduce some randomization to the algorithm.